
vLLM サーバー のセットアップと Open WebUI の接続設定
解説
DGX Spark に、vLLMサーバーをセットアップし、起動する方法、および、起動したvLLMサーバーをOpen WebUIに接続するための、Open
WebUIの設定についてまとめます。
vLLMサーバー の実行環境として、NVIDIAから提供されているDockerイメージを利用します。
前提
「Open WebUI ( Ollamaバンドル版 ) の動作環境の構築」を実施していない場合は、実施します。
vLLM コンテナ起動コマンド
Open WebUI Dockerイメージのコンテナ起動コマンドは、NVIDIA NGC Catalog サイトの vLLM Dockerイメージ のページに記載があり、以下です。
コマンドオプション解説
- --gpus all
- NVIDIA GPUサポート付きで実行します。
- -it
- インタラクティブモードで実行します。
- --rm
- コンテナを終了したらコンテナを削除します。
- nvcr.io/nvidia/vllm:xx.xx-py3
- 起動するコンテナの元となるイメージを指定します。
コンテナタグ「xx.xx-py3」は、NVIDIA NGC Catalog サイトの vLLM Dockerイメージ のページ を確認し、指定します。
2026年1月現在の最新のコンテナタグは「25.12.post1-py3」でした。
vLLM コンテナ起動スクリプトファイルの作成
コンテナ起動コマンドは文字数が多いので、実行する際にタイピングするのが少し面倒です。短い文字数のタイピングで実行できるようにスクリプトファイル化します。
今回は「docker-run-vllm.sh」というスクリプトファイルを作成することとしました。
以下のコマンドを実行し「docker-run-openwebui.sh」を作成します。
内容を以下のようにします。
コマンドオプション解説
- -it
- インタラクティブモードで起動します。
- --gpus all
- NVIDIA GPUサポート付きで実行します。
- -p 8000:8000
- ホストのポート8000にアクセスすると、コンテナの内部でポート8000で動作しているアプリケーションに接続します。
コンテナの内部でポート8000で起動するvLLMサーバーに、ホストのポート8000から接続できるようにします。 - -v vllm-cache:/root/.cache/huggingface
- Dockerボリューム「vllm-cache」をコンテナの「/root/.cache/huggingface」ディレクトリとしてマウントします。 vLLMサーバーは、モデルを「/root/.cache/huggingface」ディレクトリ内に保存します。コンテナを削除してもモデルが削除されないように、Dockerボリュームをマウントします。Dockerボリュームは、Dockerが管理するボリュームです。
- --name vllm-server
- 起動したコンテナに「vllm-server」という名前を付けます。
- nvcr.io/nvidia/vllm:25.12.post1-py3
- 起動するコンテナの元となるイメージを指定します。
コンテナタグ「xx.xx-py3」は、NVIDIA NGC Catalog サイトの vLLM Dockerイメージ のページ を確認し、指定します。
2026年1月現在の最新のコンテナタグ「25.12.post1-py3」を指定しています。
「ctrl + o」を押下し、ファイルを上書き保存します。
「ctrl + x」を押下し、ファイルを閉じます。
以下のコマンドを実行し、スクリプトファイルに実行権限を付与します。
vLLM コンテナの起動
以下のコマンドを実行し、vLLM コンテナを起動します。
初回のコンテナ起動は、コンテナイメージのダウンロードと解凍が行われるため、時間を要します。
コンテナが起動すると、Terminalでの表示が「root@ホスト名:/workspace#」に変わり、コンテナ上での作業になります。
vLLM サーバーの起動
以下のコマンドを実行し、vLLM サーバーを起動します。
コマンド解説
- vllm serve nvidia/Qwen3-8B-FP4
- vllmサーバーをLLMモデルを指定して起動します。
vLLMでサポートされているLLMモデルは、「vLLM for Inference | DGX Spark」で確認できます。
ここでは、LLMモデルとして「nvidia/Qwen3-8B-FP4」を指定しています。 - --host 0.0.0.0
- vLLMサーバーにLAN 内からアクセスできるようにします。
- --port 8000
- vLLMサーバーの待ち受けポートを指定します。
初回のサーバー起動は、LLMモデルのダウンロードが行われるため、時間を要します。
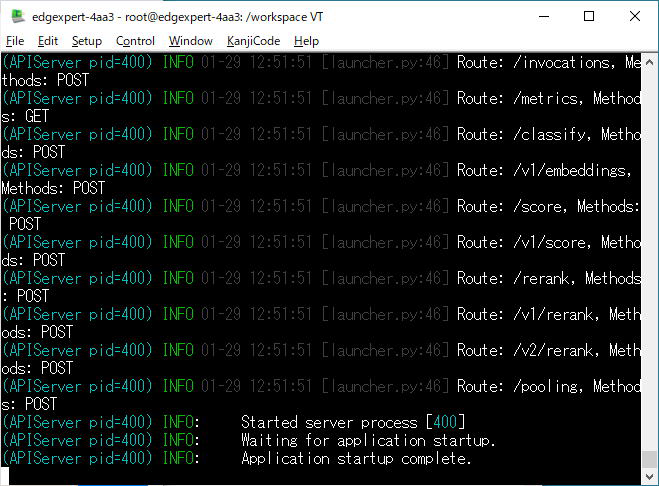
vLLM サーバーが起動すると、以下のようなメッセージが表示されます。
初回起動時のTerminal画面
vLLM サーバーの動作確認
別のターミナルを開き、以下のコマンドを実行します。
コマンド解説
- curl http://localhost:8000/v1/chat/completions
- コマンドラインから vLLMサーバー にHTTPリクエストを送信します。
- -H "Content-Type: application/json"
- 送信するリクエストのHTTPヘッダーを指定します。送信するコンテントのタイプは、jsonフォーマットのデータです。
- -d
- 送信するデータを指定します。データはjsonフォーマットです。
- "model": "nvidia/Qwen3-8B-FP4"
- vLLM サーバーの起動時に指定したLLMモデルを指定します。
- "messages": [{"role": "user", "content": "元気ですか?"}]
- LLMモデルに送信するメッセージを指定します。ここでは送信するメッセージのcontentとして「元気ですか?」を指定しています。
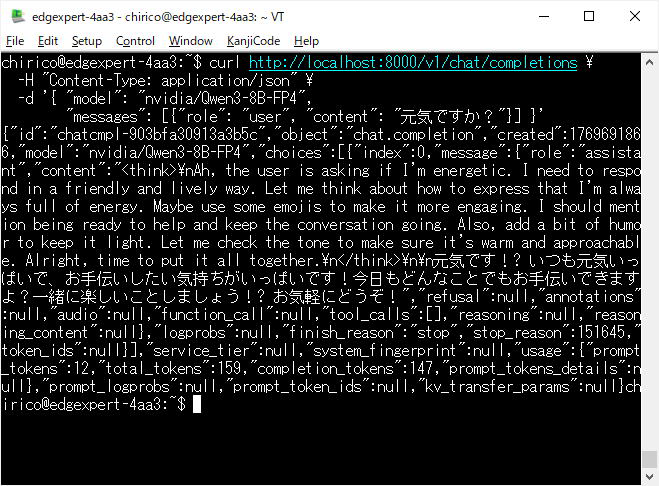
コマンド実行の結果として、HTTPレスポンスが表示されます。
HTTPレスポンスには、送信したメッセージの意味解釈や、返答文の思考過程があります。
送信したメッセージの返答として、
「元気です! いつも元気いっぱいで、お手伝いしたい気持ちがいっぱいです!今日もどんなことでもお手伝いできますよ?一緒に楽しいことしましょう!
お気軽にどうぞ!」
を得ました。
コマンドを実行し、レスポンスを得たTerminal画面
vLLM サーバーの終了と、vLLM コンテナの終了
一旦、vLLM サーバーを終了し、vLLM コンテナを終了します。
vLLM サーバーを起動したターミナルにて、「ctrl + c」を押下します。
vLLM サーバーが終了します。
以下のコマンドを実行し、vLMM コンテナを終了します。
コンテナが終了すると、Terminalでの表示が「ユーザー名@ホスト名:/~$」に変わり、ホスト上での作業に戻ります。
コンテナ起動スクリプトの変更とコンテナの再起動
Open WebUI コンテナと、vLLM コンテナを、 同一のdockerネットワークに入れることによって、Open WebUI の設定において、DGX SparkのIPアドレスではなく、dockerネットワーク名を指定できるようにします。(DGX Sparkを固定IPアドレスで運用していない場合の対応方法の一つとして実施します)
dockerネットワークの作成
以下のコマンドを実行し、dockerネットワーク「llm-net」を作成します。
Open WebUI コンテナ起動スクリプトの変更とコンテナの再起動
Open WebUI コンテナ起動スクリプトファイル「docker-run-openwebui.sh」の内容を変更します。
コンテナ起動コマンドのコマンドオプションに「--network llm-net」を追記します。
「docker-run-openwebui.sh」の内容を以下のようにします。
以下の一連のコマンドを実行し、Open WebUI コンテナを再起動します。
コンテナが起動すると、コンテナはバックグラウンドで起動され、ホスト上での作業のままです。
vLLM コンテナ起動スクリプトの変更とコンテナの再起動
vLMM コンテナ起動スクリプトファイル「docker-run-vllm.sh」の内容を変更します。
内容を以下のようにします。
コマンドオプション解説
- -d
- Detachモードで実行します。コンテナをバックグラウンドで起動します。
- --gpus all
- NVIDIA GPUサポート付きで実行します。
- -p 8000:8000
- ホストのポート8000にアクセスすると、コンテナの内部でポート8000で動作しているアプリケーションに接続します。
コンテナの内部でポート8000で起動するvLLMサーバーに、ホストのポート8000から接続できるようにします。 - -v vllm-cache:/root/.cache/huggingface
- Dockerボリューム「vllm-cache」をコンテナの「/root/.cache/huggingface」ディレクトリとしてマウントします。 vLLMサーバーは、モデルを「/root/.cache/huggingface」ディレクトリ内に保存します。コンテナを削除してもモデルが削除されないように、Dockerボリュームをマウントします。Dockerボリュームは、Dockerが管理するボリュームです。
- --name vllm-server
- 起動したコンテナに「vllm-server」という名前を付けます。
- --restart always
- コンテナの自動再起動を有効にします。OSを再起動したとき、コンテナが異常終了したとき、Dockerデーモンを再起動したとき、本コンテナは再起動します。
- --network llm-net
- コンテナをdockerネットワーク「llm-net」に入れます。
- nvcr.io/nvidia/vllm:25.12.post1-py3
- 起動するコンテナの元となるイメージを指定します。
コンテナタグ「xx.xx-py3」は、NVIDIA NGC Catalog サイトの vLLM Dockerイメージ のページ を確認し、指定します。
2026年1月現在の最新のコンテナタグ「25.12.post1-py3」を指定しています。 - vllm serve nvidia/Qwen3-8B-FP4
- コンテナの内部で vllmサーバーをLLMモデルを指定して起動します。
vLLMでサポートされているLLMモデルは、「vLLM for Inference | DGX Spark」で確認できます。
ここでは、LLMモデル「nvidia/Qwen3-8B-FP4」を指定しています。
- --host 0.0.0.0
- vLLMサーバーにLAN 内からアクセスできるようにします。
- --port 8000
- vLLMサーバーの待ち受けポートを指定します。
以下の一連のコマンドを実行し、vLLM コンテナを再起動します。
コンテナが起動すると、コンテナはバックグラウンドで起動され、ホスト上での作業のままです。
Open WebUIの接続設定
Open WebUI と vLLM サーバー とを接続する設定を行います。
同一ネットワーク上のPCのブラウザアプリ(ChromeやEdge)から、
http://[DGX Spark のホスト名]:3000
にアクセスします。
Open WebUI の画面が表示されます。
画面右上の「ユーザーアイコン」をクリックします。
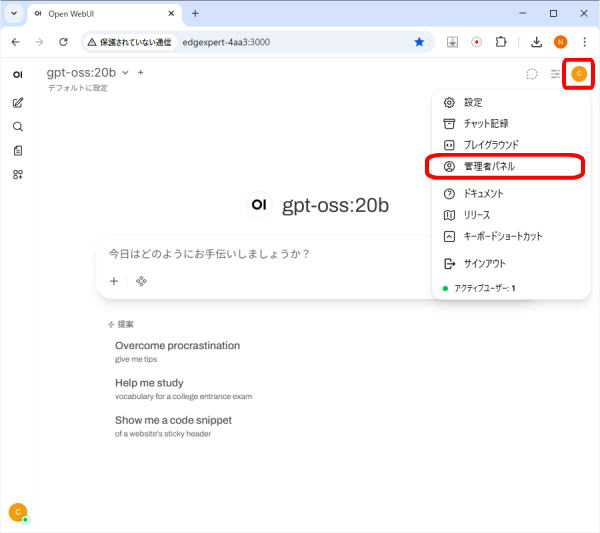
プルダウンメニューの「管理者パネル」をクリックします。
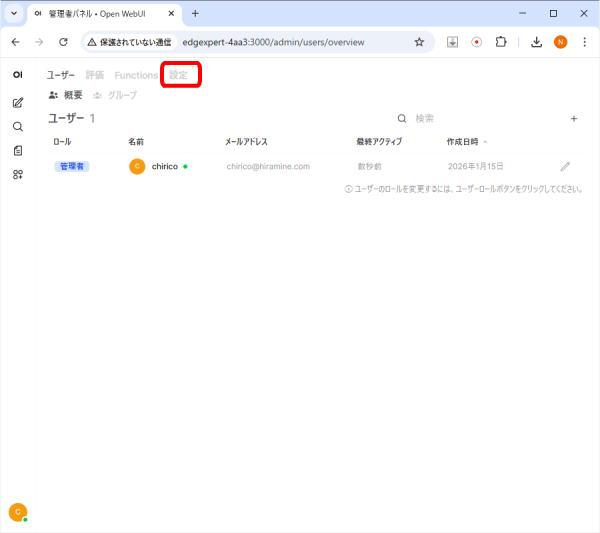
画面上部の「設定」をクリックします。
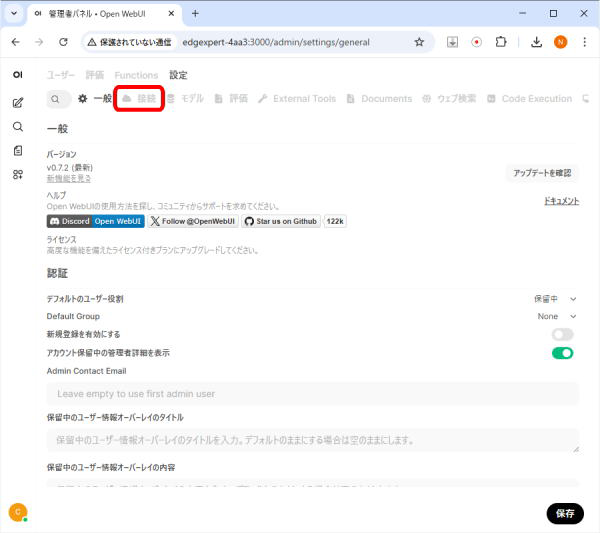
画面上部の「接続」をクリックします。
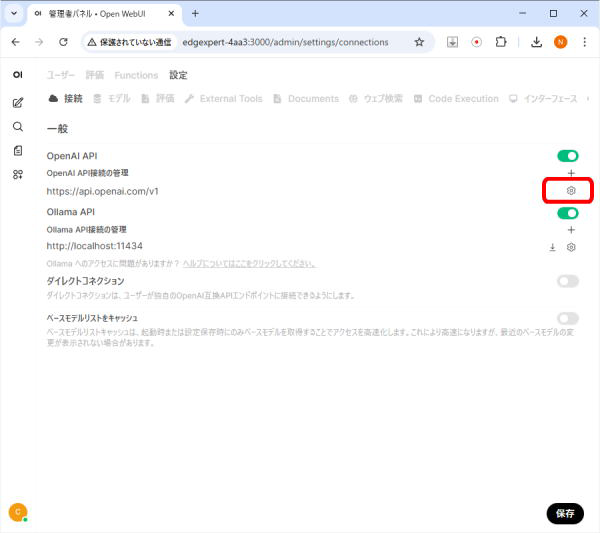
「OpenAI API」の項目のURL欄「https://api.openai.com/v1」の右側の「歯車アイコン」をクリックします。
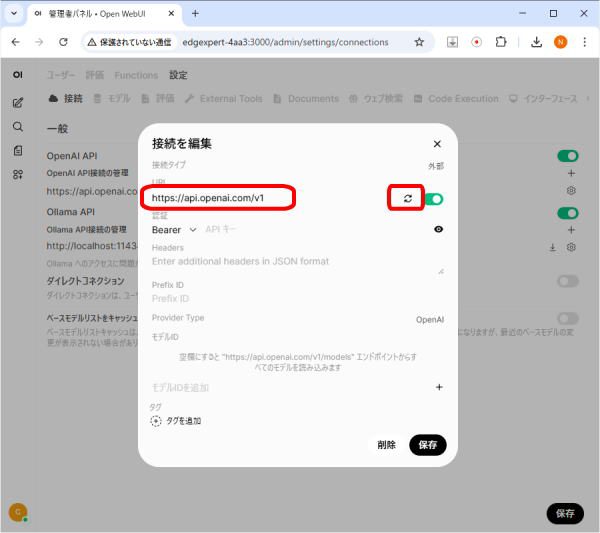
「接続を編集」ポップアップの「URL」の設定を以下に変更します。
http://vllm-server:8000/v1
(「https」ではなく「http」に変更します)
「URL」の右側の「接続を確認」アイコンをクリックします。
「サーバー接続が確認されました」メッセージが表示されます。
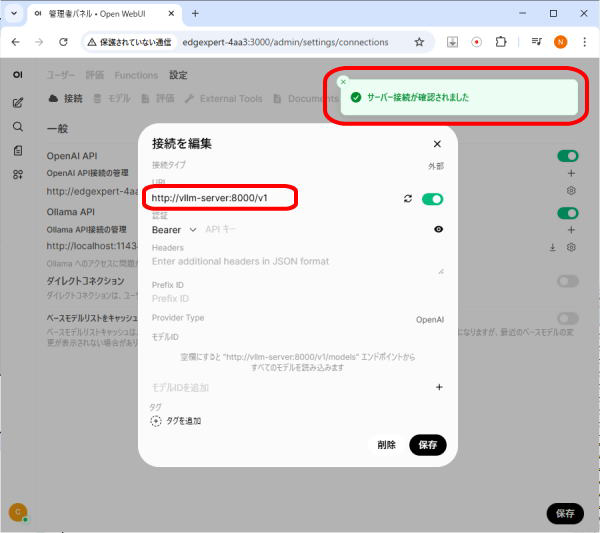
「接続を編集」ポップアップの「保存」をクリックします。
「OpenAI API」の項目のURL欄が「http://vllm-server:8000/v1」に変わりました。
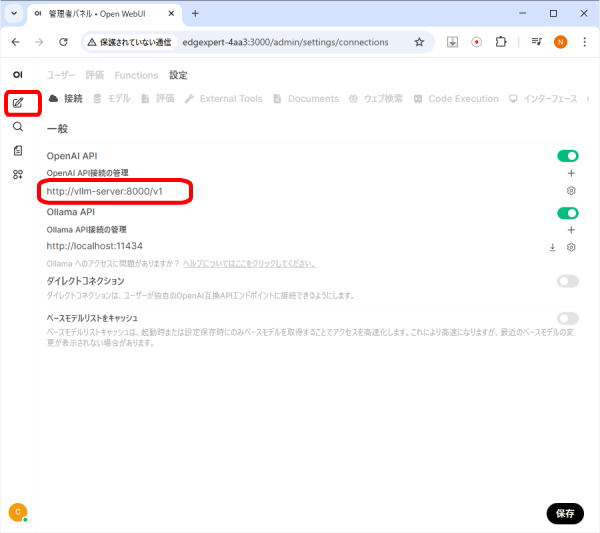
画面右下の「保存」をクリックします。
画面左の「新しいチャット」アイコンをクリックします。
vLLMサーバーとの接続の結果として、LLMモデルとして、vLLMサーバー起動時に指定したLLMモデルが選択されています。
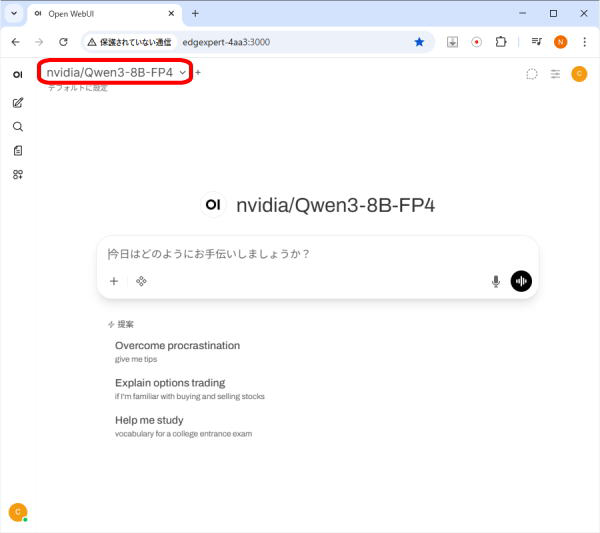
LLMモデルとのチャット
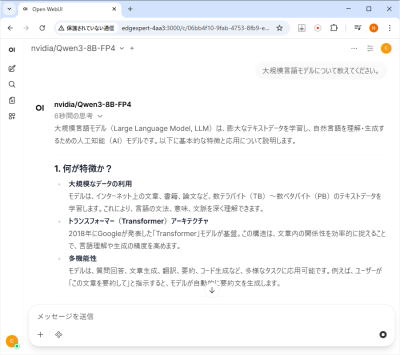
念のため、ブラウザの Open WebUI のページで、「F5」キーを押し、ページの再読み込みを行います。
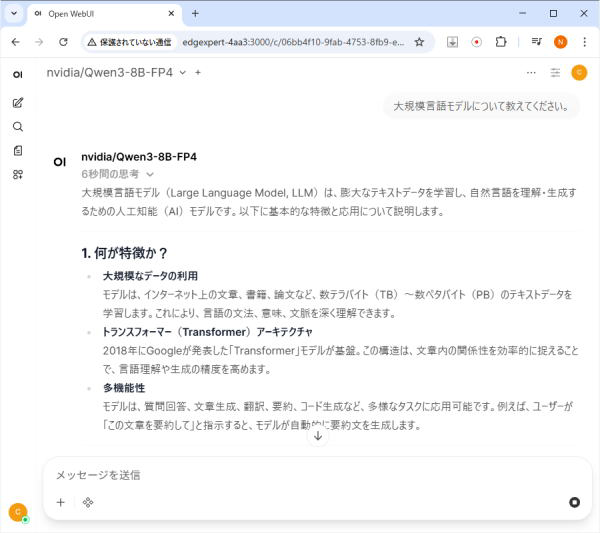
メッセージ入力欄にテキストを入力し、エンターキーを押下すると、応答が開始します。
「大規模言語モデルについて教えてください。」と入力し、回答を生成した画面
vLLM サーバーの停止、再開
コンテナをコマンドオプション「restart always」を指定して起動しているので、OSを再起動したとき、コンテナが異常終了したとき、Dockerデーモンを再起動したとき、本コンテナは再起動します。
サーバーの停止
サーバーを停止するするには、以下を実施します。
以下のコマンドを実行し、自動再起動を停止します。
以下のコマンドを実行し、コンテナを停止します。
サーバーの再開
停止したサーバーを再開するには、以下を実施します。
以下のコマンドを実行し、自動再起動を有効にします。
以下のコマンドを実行し、コンテナを起動します。
参考) クリーンアップ
構築した「vLLM サーバー の動作環境」を削除する場合は、以下を実施します。
Open WebUI の接続設定を元の設定に戻します。
具体的には、「http://vllm-server:8000/v1」に変更した設定を、「https://api.openai.com/v1」に戻します。
以下のコマンドを実行し、vLLM コンテナを停止します。
以下のコマンドを実行し、vLLM コンテナを削除します。
以下のコマンドを実行し、vLLM Dockerイメージを削除します。
以下のコマンドを実行し、Dockerボリューム「vllm-cache」を削除します。
以上で、構築した「vLLM サーバー の動作環境」が削除されました。
参考ウェブサイト
| WEBサイト | コメント |
|---|---|
| vLLM for Inference | DGX Spark | NVIDIA社のAI開発者向けポータルサイト上の DGX Spark で vLLM を動かす手順の説明 |