
Stable Diffusion に必要なPythonパッケージのインストール
解説
Jetson Orin Nano に、Stable Diffusion の動作環境を構築する方法についてまとめます。
Stable Diffusion の動作環境のベースとなる環境として、NVIDIA社から提供されているDockerコンテナの中から、機械学習開発用のコンテナ「L4T
ML」を利用します。
このページでは、Stable Diffusion に必要なPythonパッケージをインストールします。
注意)このページの作業は、完了までに、5時間ほどの時間を必要とします。(人の作業は30分も必要ありませんが、途中、xformersのビルドに4時間半ほど要します)。
前提
Stable Diffusion の動作の際は、多くのメモリを必要します。また多くの処理時間を必要とします。また多くのディスク容量を必要とします。
これらを踏まえ、以下を実施済みの状態の Jetson Orin Nano を前提とします。
- ブートデバイスのNVMe SSDへの変更
- Jetson Orin Nano の既定のブートデバイスは、SDカードです。SDカードは、読み書きの速度が速くはなく、また、ディスク容量も多くはありません。ブートデバイスをNVMe
SSDに変更しておきます。
参考)
・Jetson Orin Nano で日本語LLMを動かしてみた
・Jetson Orin NanoのNVMe SSDを使ったOSイメージのセットアップ手順 #NVIDIA - Qiita
・Jetson Orin Nano開発者キットでHシリーズNVMe SSDを使う! │ HAGIWARA Solutions - デスクトップ環境の無効化
- デスクトップ環境は多くのメモリを必要としますが、Stable Diffusion の動作においては必要ないので、無効化しておきます。
参考)
・Memory optimization - NVIDIA Jetson AI Lab
・Jetson Orin Nano で日本語LLMを動かしてみた
・Llama 2をJetson Orin Nanoで起動してみる #LLM - Qiita - その他サービスを無効化
- カメラ機能を使うときに動くバックグラウンドサービス「nvargus-daemon.service」は必要ないので、無効化しておきます。
- 参考)
・Memory optimization - NVIDIA Jetson AI Lab
・Jetson Orin Nano で日本語LLMを動かしてみた
・Llama 2をJetson Orin Nanoで起動してみる #LLM - Qiita - 参考)
- スワップ領域の拡張
- Jetson Orin Nano は既定では、ZRAMと呼ばれる領域に3.2Gほどのスワップ領域が作成されています。16GBのスワップ領域をNVMe
SSD上に作成しておきます。また、ZRAMは無効化しておきます。
参考)
・スワップ領域の確認と拡張 - hiramine.com
・Memory optimization - NVIDIA Jetson AI Lab
・Jetson Orin Nano で日本語LLMを動かしてみた
・Llama 2をJetson Orin Nanoで起動してみる #LLM - Qiita
使用した Jetson Orin Nano は、以下についても実施済みです。
- Sambaのインストール と設定
- 別のマシンから、ファイル操作をできるようにしておくと、何かと便利なので、Sambaをインストールしておきます。
「/home/(ログインユーザー名)」のディレクトリをSamba共有しておきます。
参考)
・Sambaのインストールと設定と接続
機械学習開発用のコンテナ
NVIDIA社から提供されているDockerコンテナの中から、Jetsonに最適化された機械学習開発用のコンテナ「L4T ML」を利用することとします。
提供元ページは以下です。
NVIDIA L4T ML | NVIDIA NGC
※L4T : Linux for Tegra の略です。Jetson Linuxのことです。Jetson Linuxは、以前は、Linux for
Tegraという名称でした。Tegraとは、NVIDIA社のSoCシリーズの名前です。Jetsonシリーズは、NVIDIAのTegraを搭載しています。
※ML : Machine Learningの略です。機械学習のことです。
コンテナ起動コマンド
機械学習用のコンテナ「L4T ML」の起動コマンドは、提供元ページに記載があり、以下です。
コマンドオプション解説
- -it
- インタラクティブモードで実行します
- --rm
- コンテナを終了したらコンテナを削除します。(コンテナを終了してもコンテナを削除したくない場合は、このオプションは外します)
- --runtime nvidia
- l4t-base コンテナの実行中に NVIDIA コンテナランタイムを使用します。
- --network host
- コンテナが Jetson ホストのネットワークとポートを使用できるようにします。
イメージのタグの確認
コンテナ起動コマンドの「<tag>」については、実行する Jetson Orin Nano の環境に合わせたタグを指定する必要があります。
まず、「OSバージョンの確認」等を参考に、Jetson Linux とJetPackのバージョンを確認します。
使用している Jetson Orin Nano の、Jetson Linux のバージョンは、 36.4.4 で、JetPackのバージョンは、 6.2.1 でした。
続いて、環境に合わせたタグを、提供元ページ「NVIDIA L4T ML | NVIDIA NGC」から確認します。
2025年8月13日現在、Jetson Linux のバージョン 36.4.4 のタグは存在しないため、Jetson Linux のバージョン
36.2.0 のタグ「r36.2.0-py3」を使用します。
コンテナにマウントするホスト側のディレクトリの作成
作業用ディレクトリを作成します。作成したディレクトリは、コンテナにマウントします。
以下のコマンドを実行し、ディレクトリを作成します。今回はユーザーのホームディレクトリ下に「work-l4t-ml-sd」というフォルダを作成することとしました。
(機械学習用のコンテナ「L4T ML」(l4t-ml)を利用した「Stable Diffusion」(sd)の動作環境が構築されたコンテナの作業用(work)のディレクトリ)
ホストのディレクトリをコンテナにマウントしてコンテナを起動するコマンドの書式は以下です。
コンテナ起動スクリプトファイルの作成
コンテナ起動コマンドは文字数が多いので、実行する際にタイピングするのが少し面倒です。短い文字数のタイピングで実行できるようにスクリプトファイル化します。
今回は「docker-run-sd.sh」というスクリプトファイルを作成することとしました。
「docker-run-sd.sh」というスクリプトファイルを作成し、内容を以下のようにします。
コマンドオプション解説
- -it
- インタラクティブモードで実行します
- --runtime nvidia
- l4t-base コンテナの実行中に NVIDIA コンテナランタイムを使用します。
- --network host
- コンテナが Jetson ホストのネットワークとポートを使用できるようにします。
- --volume ~/work-l4t-ml-sd:/work
- ホストの「work-l4t-ml-sd」ディレクトリをコンテナの「/work」ディレクトリとしてマウントします。
- --name l4t-ml-sd-dev
- 起動したコンテナに「l4t-ml-sd-dev」という名前を付けておきます。後ほどDockerイメージ化するときに付けた名前を使用します。
起動したコンテナ上で、Stable Diffusionの動作環境を構築し、Dockerイメージ化し再利用します。そのために「--rm」オプションは付けません。 - nvcr.io/nvidia/l4t-ml:r36.2.0-py3
- 起動するコンテナの元となるイメージとして、「nvcr.io/nvidia/l4t-ml:r36.2.0-py3」を指定します。タグは実行する Jetson Orin Nano の環境に合わせたタグにします。
以下のコマンドを実行し、スクリプトファイルに実行権限を付与します。
コンテナの起動
以下のコマンドを実行し、「L4T ML」コンテナを起動します。
初回のコンテナ起動は、コンテナイメージのダウンロードと解凍が行われるため、時間を要します。
コンテナが起動すると、Terminalでの表示が「root@ホスト名:/#」に変わり、コンテナ上での作業になります。
以降の作業は、指定がない場合は、コンテナ上での作業です。
Stable Diffusion を動かすためのPythonモジュールのインストール
以下のコマンドを実行し、インストールされている torch(≒PyTorch) のバージョンを確認します。
「torch @ file:///opt/torch-2.1.0-cp310-cp310-linux_aarch64.whl#sha256=(略)」と表示されました。
torchは、version 2.1.0がインストールされていました。
「requirements.txt」ファイルを作成し、ファイルの内容を以下のようにします。
機械学習開発用のコンテナ「L4T ML」には、Jetsonに最適化された torch がインストールされています。torch がアップグレードされないように、インストールされているtorchのバージョンを書いておきます。(torch
がアップグレードされた場合、Jetsonに最適化されていなバージョンにアップグレードされてしまいます)
diffusers は、Stable Diffusion のPythonプログラミングで必要なPythonモジュールです。
transformers、accelerate、xformers は、diffusers に関連し、必要なモジュールです。(依存関係を考慮したバージョンを指定しています)
以下のコマンドを実行し、xformers のコンパイルのGPUアーキテクチャを指定します。(この指定をしない場合、全 GPU アーキテクチャ向けにコンパイルが行われ、無駄に時間を要する可能性があります。)
以下のコマンドを実行し、xformersのコンパイルのスレッド数を「1」にします。(この指定をしない場合、コンパイルがマルチスレッドで行われ、メモリ使用量が多くなり、メモリ不足によりxformersのコンパイルに失敗する可能性があります。xformersのコンパイルには多くのメモリを必要とするので、メモリ削減を行います。)
以下のコマンドを実行し、Stable Diffusion を動かすためのPythonモジュールをインストールします。
「-r requirements.txt」により、requirements.txt に書かれたパッケージをまとめてインストールします。
「--upgrade-strategy only-if-needed」を指定し、必要な場合にだけ依存パッケージをアップグレードし、インストール済みの依存パッケージはアップグレードの必要がない場合はアップグレードしないようにします。
「--no-cache-dir」を指定し、パッケージをダウンロードしたらキャッシュせず、その場で展開してビルドするようにします。(この指定をしない場合、パッケージをダウンロードしたら、キャッシュ保存し、展開してビルドします。一時的に、圧縮版、展開版、メモリ上のビルドファイルが同時に存在することがあり、メモリ使用量が多くなります。結果として、メモリ不足によりxformersのコンパイルに失敗する可能性があります。xformersのコンパイルには多くのメモリを必要とするので、メモリ削減を行います。)
4時間半ほど待ちます。(「Building wheel for xformers (setup.py) ...」に4時間半ほど要します)。
Pythonモジュールのインストールが終了したときの、Terminal画面
Hugging Face のキャッシュディレクトリの変更
Pythonプログラムでの画像生成の試行に先だって、Hugging Face のキャッシュディレクトリを、コンテナ内のディレクトリから、ホスト側のディレクトリに変更します。
(Dockerイメージのファイルサイズ削減のために行います。
この後の画像生成において、Hugging Face のキャッシュは、10GB以上になります。
Hugging Face のキャッシュディレクトリは、既定では、コンテナ内の「/root/.cache/huggingface/」です。
Hugging Face のキャッシュディレクトリの変更を行わなかった場合、Dockerイメージ化の際に、Hugging Face のキャッシュも含めてイメージ化されます。
Hugging Face のキャッシュディレクトリの変更を行った場合、Dockerイメージ化の際に、Hugging Face のキャッシュはイメージ化に含まれません。結果、Dockerイメージのファイルサイズ削減となります)
以下のコマンドを実行します。
次回以降のコンテナ起動時にも適用されるように、「/root/.bashrc」ファイルの末尾に、以下を追記します。(ファイル名の先頭には、「ドット」がひとつあります)
画像生成の試行
以下のコマンドを実行し、作業用ディレクトリに移動します。
「hello-diffusers.py」ファイルを作成し、ファイルの内容を以下のようにします。
以下のコマンドを実行し、画像生成をし、結果を確認します。
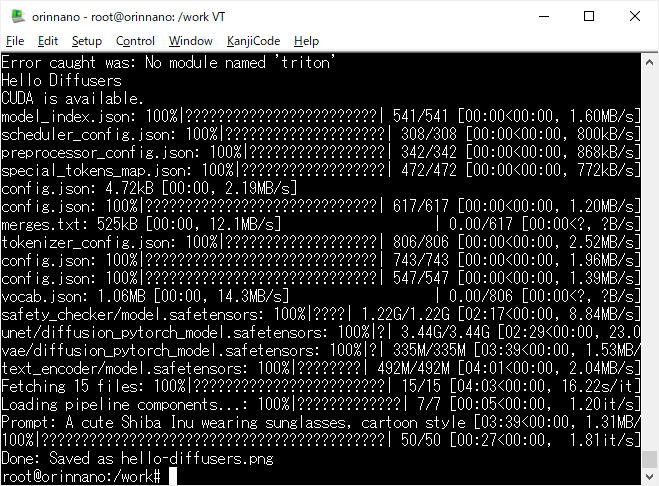
初回実行時は、Stable Diffusion 推論モデル「stable-diffusion-v1-5/stable-diffusion-v1-5」の複数のファイルのダウンロード等があり時間を要します。(時間は、ネットワーク環境等に依存します)
画像生成の試行、初回実行時の、Terminal画面
ホスト側の「~/work-l4t-ml-sd」をSamba共有でアクセスできるようにしておき、同一ネットワーク上のPCから生成画像ファイルにアクセスします。
初回実行時の生成画像

2回目以降は、30秒前後で画像生成されます。
2回目実行時の生成画像

コンテナの終了
以下のコマンドを実行し、コンテナを終了します。
コンテナが終了すると、Terminalでの表示が「ユーザー名@ホスト名:/~$」に変わり、ホスト上での作業に戻ります。
以降の作業は、指定がない場合は、ホスト上での作業です。
コンテナのイメージ化
以下のコマンドを実行し、コンテナをイメージ化します。
l4t-ml-sd-dev : イメージ化するコンテナの名前
l4t-ml-sd:v1 : 作成するイメージの名前「l4t-ml-sd」、タグ「v1」。
不要となったコンテナの削除
以下のコマンドを実行し、不要となったコンテナを削除します。
l4t-ml-sd-dev : 削除するコンテナの名前
作成したイメージを用いてコンテナの起動
コンテナ起動スクリプトファイル「docker-run-sd.sh」を以下の内容に修正します。
コンテナを終了したらコンテナを削除するように「--rm」オプションを追記します。
コンテナに名前を付ける「--name」オプションは削除します。
起動するコンテナの元となるイメージを、「l4t-ml-sd:v1」に変更します。
以下のコマンドを実行します。
構築した Stable Diffusion の動作環境のコンテナが起動します。
コンテナでの作業を終了するには「exit」コマンドを実行します。
関連ページ
Stable Diffusion に必要なPythonパッケージのインストール - 【本ページ】
Stable Diffusion WebUI (AUTOMATIC1111版) の動作環境の構築
Stable Diffusion WebUI (Forge版) の動作環境の構築
Stable Diffusion WebUI (reForge版) の動作環境の構築